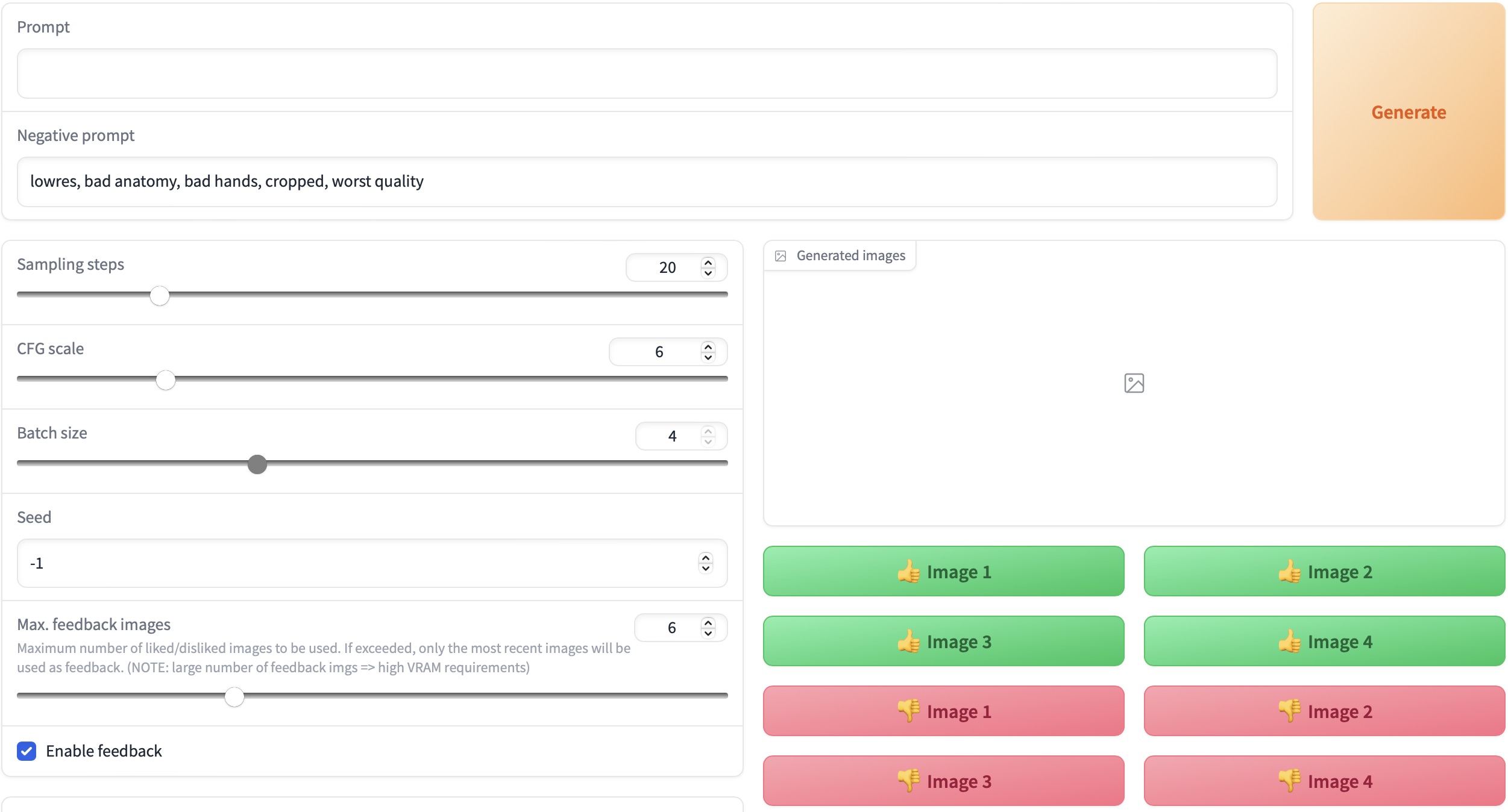
In this study, we investigate the integration of iterative human feedback into diffusion-based text-to-image models to enhance user experience and output quality. We introduce FABRIC (Feedback via Attention-Based Reference Image Conditioning), a training-free approach that conditions the diffusion process on a set of feedback images, applicable to a wide range of popular diffusion models. We propose a comprehensive evaluation methodology for a rigorous assessment of our approach and demonstrate that generation results improve over multiple rounds of iterative feedback, optimizing user preferences. This work has potential applications in personalized content creation and customization, contributing to the advancement of text-to-image generation research.
@misc{vonrütte2023fabric,
title={FABRIC: Personalizing Diffusion Models with Iterative Feedback},
author={Dimitri von Rütte and Elisabetta Fedele and Jonathan Thomm and Lukas Wolf},
year={2023},
eprint={2307.10159},
archivePrefix={arXiv},
primaryClass={cs.CV}
}